We're always interested in getting feedback. E-mail us if you like this guide, if you think that important material is omitted, if you encounter errors in the code examples or in the documentation, if you find any typos, or generally just if you feel like e-mailing. Mail to Karel Kubat (karel@icce.rug.nl) or use an e-mail form . Please state the concerned document version, found in the title. If you're interested in a printable PostScript copy, use the form . or better yet, pick up your own copy viaftpat ftp.icce.rug.nl/pub/http ,
This chapter presents a number of concrete examples of programming in
C++. Items from this document such as virtuality, static members,
etc. are rediscussed. Examples of container classes are shown.
A reoccurring task of many programs is the storage of data, which are then
sorted, selected, etc.. Storing data can be as simple as maintaining an array
of ints, but can also be much more complex, such as maintaining file
system information by the kernel of an operating system.
In this section we take a closer look at the storage of generic objects in
memory (i.e., during the execution of a program). Conforming to the
object-oriented recipe we shall develop two classes: a class Storage,
which stores objects, and a class Storable, the prototype of objects
which can be stored.
As far as the functionality of the class Storage is concerned, objects
can be added to the storage and objects can be obtained from the storage. Also
it must be possible to obtain the number of objects in the storage.
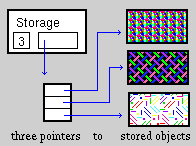
As far as the internal data organization of the storage is concerned, we
opt for an approach in which Storage maintains an array which can be
reallocated, consisting of pointers to the stored objects.
The internal organization of the class Storage is illustrated in the
following figure:
The usage (interface) of the class Storage is contained in three member
functions. The following list describes these member functions and mentions
the class Storable, more on this later.
add(Storable const *newobj) adds an object to the
storage. The function reallocates the array of pointers to accommodate one
more and inserts the address of the object to store.
Storable const *get(int index) returns a pointer
to the object which is stored at the index'th slot.
int nstored() returns the number of objects in
the storage.
There are two distinct design alternatives for the function add(). These
considerations address the choice whether the stored objects (the squares on
the right side of figure
StorageFigure
) should be copies of the
original objects, or the objects themselves.
In other words, should the function add() of the class Storage:
These considerations are not trivial. Consider the following example:
Storage
store;
Storable
something;
store.add (something); // add to storage
// let's assume that Storable::modify () is defined
something.modify (); // modify original object,
Storable
*retrieved = store.get (0); // retrieve from storage
// NOW: is "*retrieved" equal to "something" ?!
If we choose to store (addresses of) the objects themselves, then at the end
of the above code fragment, the object pointed to by retrieved will equal
something. A manipulation of previously stored objects thereby alters the
contents of the storage.
If we choose to store copies of objects, then obviously *retrieved
will not equal something but will remain the original, unaltered, object.
This approach has a great merit: objects can be placed into storage as a
`safeguard', to be retrieved later when an original object was altered or even
ceased to exist. In this implementation we therefore choose for this approach.
The fact that copies of objects should be stored presents a small problem. If
we want to keep the class Storage as universal as possible, then the
making of a copy of a Storable object cannot occur here. The reason for
this is that the actual type of the objects to store is not known in advance.
A simplistic approach, such as the following:
void Storage::add (Storable const *obj)
{
Storable
*to_store = new (*obj);
// now add to_store instead of obj
.
.
}
shall not work. This code attempts to make a copy of obj by using the
operator new, which in turn calls the copy constructor of Storable.
However, if Storable is only a base class, and the class of the object to
store is a derived class (say, a Person), how can the copy constructor of
the class Storable create a copy of a Person?
The making of a copy therefore must lie with the actual class of the
object to store, i.e., with the derived class. Such a class must have the
functionality to create a duplicate of the object in question and to
return a pointer to this duplicate. If we call this function duplicate()
then the code of the adding function becomes:
void Storage::add (Storable const *obj)
{
Storable
*to_store = obj->duplicate ();
// now add to_store instead of obj
.
.
}
The function duplicate() is called in this example by using a pointer to
the original object (this is the pointer obj). The class Storable is
in this example only a base class which defines a protocol, and not the class
of the actual objects which will be stored. Ergo, the function
duplicate() need not be defined in Storable, but must be
concretely implemented in derived classes. In other words, duplicate() is
a pure virtual function.
Using the above discussed approach we can now define the class Storable.
The following questions are of importance:
Storable need a default constructor, or
possibly other constructors such as a copy constructor?
The answer is no. Storable will be a bare prototype, from which
other classes will be derived.
Storable need a destructor? Should this
destructor be (pure) virtual?
Yes. The destructor will be called when, e.g., a Storage object
ceases to exist. It is quite possible that classes which will be derived
from Storable will have their own destructors: we should therefore
define a virtual destructor, to ensure that when an object pointed to
by a Storable* is deleted, the actual destructor of the derived class
is called.
The destructor however should not be pure virtual. It is quite
possible that the classes which will be derived from Storable will
not need a destructor; in that case, an empty destructor function should
be supplied.
The class definition and its functions are given below:
class Storable
{
public:
virtual ~Storable (void);
virtual Storable *duplicate (void) const = 0;
};
Storable::~Storable ()
{
}
To show how (existing) classes can be converted to derivation from a
Storable, consider the below class Person from section
Person
. This class is re-created here, conforming to Storable's
protocol (only the relevant or new code is shown):
class Person: public Storable
{
// copy constructor
Person (Person const &other);
// assignment
Person const &operator= (Person const &other);
// duplicator function
Storable *duplicate () const;
.
.
}
When implementing the function Person::duplicate() we can use either the
copy constructor or the default constructor with the overloaded assignment
operator. The implementation of duplicate() is quite simple:
// first version:
Storable *Person::duplicate () const
{
// uses default constructor in new Person
Person
*dup = new Person;
// uses overloaded assignment in *dup = *this
*dup = *this;
return (dup);
}
// second version:
Storable *Person::duplicate () const
{
// uses copy constructor in new(*this)
return (new (*this));
}
The above conversion from a class Person to the needs of a Storable
supposes that the sources of Person are at hand and can be modified.
However, even if the definition of a Person class is not available, but
is e.g., contained in a run-time library, the conversion to the Storable
format poses no difficulties:
class StorablePerson: public Person, public Storable
{
public:
// duplicator function
Storable *duplicate () const;
};
Storable *StorablePerson::duplicate () const
{
return (new ( * (Person*)this ));
}
We can now implement the class Storage. The class definition is given
below:
class Storage: public Storable
{
public:
// destructors, constructor
~Storage (void);
Storage (void);
Storage (Storage const &other);
// overloaded assignment
Storage const &operator= (Storage const &other);
// functionality to duplicate storages
Storable *duplicate (void) const;
// interface
void add (Storable *newobj);
int nstored (void) const;
Storable *get (int index);
private:
// copy/destroy primitives
void destroy (void);
void copy (Storage const &other);
// private data
int n;
Storable **storage;
};
Concerning the class definition we remark:
add(), get()
and nstored(). These functions were previously discussed (see section
StorageInterface
).
Storage contains a
pointer, which addresses allocated memory.
Storage itself is derived from Storable, as can be seen
in the classname definition and in the presence of the function
duplicate(). This means that Storage objects can themselves be
placed in a Storage, thereby creating `super-storages': say, a list
of groups of Persons.
Storage defines two private functions
copy() and destroy(). The purpose of these primitive functions
is discussed in section
CopyDestroy
.
The destructor, constructors and the overloaded assignment function are listed below:
// default constructor
Storage::Storage ()
{
n = 0;
storage = 0;
}
// copy constructor
Storage::Storage (Storage const &other)
{
copy (other);
}
// destructor
Storage::~Storage ()
{
destroy ();
}
// overloaded assignment
Storage const &Storage::operator= (Storage const &other)
{
if (this != &other)
{
destroy ();
copy (other);
}
return (*this);
}
The primitive functions copy() and destroy() unconditionally copy
another Storage object, or destroy the contents of the current one. Note
that copy() calls duplicate() to duplicate the other's stored
objects:
void Storage::copy (Storage const &other)
{
n = other.n;
storage = new Storable* [n];
for (int i = 0; i < n; i++)
storage [i] = other.storage [i]->duplicate ();
}
void Storage::destroy ()
{
for (register int i = 0; i < n; i++)
delete storage [i];
delete storage;
}
The function duplicate(), which is required since Storage itself
should be a Storable, uses the copy constructor to duplicate the current
object:
Storable *Storage::duplicate () const
{
return (new (*this));
}
Finally, here are the interface functions which add objects to the storage, return them, or determine the number of stored objects:
void Storage::add (Storable const *newobj)
{
// reallocate storage array
storage = (Storable **) realloc (storage,
(n + 1) * sizeof (Storable *));
// put duplicate of newobj in storage
storage [n] = newobj->duplicate ();
// increase number of obj in storage
n++;
}
Storable *Storage::get (int index)
{
// check if index within range
if (index < 0 || index >= n)
return (0);
// return address of stored object
return (storage [index]);
}
int Storage::nstored () const
{
return (n);
}
This section shows an implementation of a binary tree in C++. Analogously
to the classes Storage and Storable (see section
Storage
)
two separate classes are used: one to represent the tree itself, and one to
represent the objects which are stored in the tree. The classes will be
appropriately named Tree and Node.
The class Node is an abstract (pure virtual) class, which defines the
protocol for the usage of derived classes with a Tree. Concerning this
protocol we remark the following:
This comparison must lie with Nodes: a Tree itself cannot
know how objects should be compared. Part of the procotol which is
required by Node is therefore:
virtual int compare (Node const *other) const = 0;
The comparing function will have to be implemented in each derived class.
Storage (see
section
Storage
), a binary tree will contain copies of
objects. The responsibility to duplicate an object therefore also lies
with Node, as defined in a pure virtual function:
virtual Node *duplicate (void) const = 0;
virtual void process (void) = 0;
Node, the responsibility to process an object is placed
with the derived class.
already_stored(), which
is however not pure virtual. The default implementation will take no
action. The function can however be redefined in a derived class:
virtual void already_stored (void);
The complete definition and declaration of the class Node is given below:
class Node
{
public:
// destructor
virtual ~Node ();
// duplicator
virtual Node* duplicate (void) const = 0;
// comparison of 2 objects
virtual int compare (Node const *other) const = 0;
// function to do whatever is needed to the node
virtual void process (void) = 0;
// called when object to add was already in the tree
virtual void already_stored (void);
};
Node::~Node ()
{
}
void Node::already_stored ()
{
}
The class Tree is responsible for the storage of objects which are
derived from a Node. To implement the recursive tree structure, the class
Tree has two private pointers as its data, pointing to subtrees: a
Tree *left and Tree *right. The information which is contained in a
node of the tree is represented as a private field Node *info.
To scan a binary tree, the class Tree offers three methods: preorder,
inorder and postorder. When scanning in preorder first a leaf in a node is
processed, then the left subtree is scanned and finally the right subtree is
scanned. When scanning inorder first the left subtree is scanned, then the
leaf itself is processed and finally the right subtree is scanned. When
scanning in postorder first the left and right subtrees are scanned and then
the leaf itself is processed.
The definition of the class Tree is given below:
class Tree
{
public:
// destructor, constructors
~Tree (void);
Tree (void);
Tree (Tree const &other);
// assignment
Tree const &operator= (Tree const &other);
// addition of a Node
void add (Node *what);
// processing order in the tree
void preorder_walk (void);
void inorder_walk (void);
void postorder_walk (void);
private:
// primitives
void copy (Tree const &other);
void destroy (void);
// data
Tree *left, *right;
Node *info;
};
As can be seen from the class definition, Tree contains pointer fields.
This means that the class will need a destructor, a copy constructor and an
overloaded assignment function to ensure that no allocation problems occur.
The destructor, the copy constructor and the overloaded assignment function
are implemented with two primitive operations copy() and destroy()
(these functions are presented later):
// destructor: destroys the tree
Tree::~Tree ()
{
destroy ();
}
// default constructor: initializes to 0
Tree::Tree ()
{
left = right = 0;
info = 0;
}
// copy constructor: initializes to contents of other object
Tree::Tree (Tree const &other)
{
copy (other);
}
// overloaded assignment
Tree const &Tree::operator= (Tree const &other)
{
if (this != &other)
{
destroy ();
copy (other);
}
return (*this);
}
The addition of a new object to the tree is a recursive process. When the
function add() is called to insert an object into the tree, there are
basically only a few possibilities:
info field of the current node can be a 0-pointer. In that
case, a duplicate of the object to add is inserted in the current node.
compare(), a pure virtual function whose implementation is required
by Node. Depending on the order the new object must be inserted in
the left or in the right subtree. These subtrees may first have
to be allocated.
already_stored() is called.
The function add() is listed below:
void Tree::add (Node *what)
{
if (! info)
info = what->duplicate ();
else
{
register int
cmp = info->compare (what);
if (cmp < 0)
{
if (! left)
{
left = new Tree;
left->info = what->duplicate ();
}
else
left->add (what);
}
else if (cmp > 0)
{
if (! right)
{
right = new Tree;
right->info = what->duplicate ();
}
else
right->add (what);
}
else
info->already_stored ();
}
}
The class Tree offers three methods of scanning a binary tree: preorder,
inorder and postorder. The three functions which define these actions are
recursive:
void Tree::preorder_walk ()
{
if (info)
info->process ();
if (left)
left->preorder_walk ();
if (right)
right->preorder_walk ();
}
void Tree::inorder_walk ()
{
if (left)
left->inorder_walk ();
if (info)
info->process ();
if (right)
right->inorder_walk ();
}
void Tree::postorder_walk ()
{
if (left)
left->postorder_walk ();
if (right)
right->postorder_walk ();
if (info)
info->process ();
}
The functions copy() and destroy() are two private member
functions which implement primitive operations of the class Tree: the
copying of the contents of another Tree or the destroying of the tree.
void Tree::destroy ()
{
delete info;
if (left)
delete left;
if (right)
delete right;
}
void Tree::copy (Tree const &other)
{
info = other.info ? other.info->duplicate () : 0;
left = other.left ? new Tree (*other.left) : 0;
right = other.right ? new Tree (*other.right) : 0;
}
Concerning this implementation we remark the following:
destroy() is recursive, even though this is not
at once visible. A statement like delete left will activate the
destructor for the Tree object which is pointed to by left; this
in turn will call destroy() etc..
copy() is recursive. The code left
= new Tree (*other.left) activates the copy constructor, which in turn
calls copy() for the left branch of the tree.
add(), nodes themselves are
duplicated with the function duplicate(). This function is supplied
by a concrete implementation of a derived class of Node.
We illustrate the usage of the classes Tree and Node with a program
that counts words in files. Words are defined as series of characters,
separated by white spaces. The program shows which words are present in which
file, and how many times.
Below is the listing of a class Strnode. This class is derived from
Node and implements the virtual functions. Note also how this class
implements the counting of words; when a given word occurs more than one time,
Tree will call the member function already_stored(). This function
simply increases the private counter variable times.
class Strnode: public Node
{
public:
// destructor, constructors
~Strnode (void);
Strnode (void);
Strnode (Strnode const &other);
Strnode (char const *s);
// assignment
Strnode const &operator= (Strnode const &other);
// functions required by Node protocol
Node* duplicate (void) const;
int compare (Node const *other) const;
void process (void);
void already_stored (void);
private:
// data
char *str;
int times;
};
Strnode::~Strnode ()
{
delete str;
}
Strnode::Strnode ()
{
str = 0;
times = 0;
}
Strnode::Strnode (Strnode const &other)
{
str = strdup (other.str);
times = other.times;
}
Strnode::Strnode (char const *s)
{
str = strdup (s);
times = 1;
}
Strnode const &Strnode::operator= (Strnode const &other)
{
if (this != &other)
{
delete str;
str = strdup (other.str);
times = other.times;
}
return (*this);
}
Node *Strnode::duplicate () const
{
return (new Strnode (*this));
}
int Strnode::compare (Node const *other) const
{
Strnode
*otherp = (Strnode *) other;
if (str && otherp->str)
return (strcmp (str, otherp->str));
if (! str && ! otherp->str)
return (0);
return ( (int) otherp->str - (int) str );
}
void Strnode::process ()
{
if (str)
printf ("%4d\t%s\n", times, str);
}
void Strnode::already_stored ()
{
times++;
}
void countfile (FILE *inf, char const *name)
{
Tree
tree;
char
buf [255];
while (1)
{
fscanf (inf, " %s", buf);
if (feof (inf))
break;
Strnode
*word = new Strnode (buf);
tree.add (word);
delete word;
}
tree.inorder_walk ();
}
int main (int argc, char **argv)
{
register int
exitstatus = 0;
if (argc > 1)
for (register int i = 1; i < argc; i++)
{
FILE
*inf = fopen (argv [i], "r");
if (! inf)
{
fprintf (stderr, "wordc: can't open \"%s\"\n",
argv [i]);
exitstatus++;
}
else
{
countfile (inf, argv [i]);
fclose (inf);
}
}
else
countfile (stdin, "--stdin--");
return (exitstatus);
}
Next Chapter, Previous Chapter
Table of contents of this chapter, General table of contents
Top of the document, Beginning of this Chapter