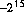
We now fill in a variety of missing details before moving to further fundamentally new facilities of C++. Some of these extra details are just included for completeness, and will not be studied extensively.
It is vitally important that programs are laid out carefully. One of the most important considerations in programming is the readability of the program. In industry and commerce one would want a readable style, and each company will have its own style so that programs written in one department can be read by users in another. There are programs ("program formatters" or "beautifiers") which can lay out a given program to comply with certain rules. Such programs cannot, of course, insert comments, or ensure that identifiers are meaningful, but the can ensure that the indentation is correct, and that there is a reasonable amount of spacing.
There are also "program editors" or "structure editors" which enforce program layout as you create the program. They operate in different ways, I may describe some in the lecture.
A number of ordinary text editors such as "vi" and "emacs" have optional facilities for automatically laying out programs.
When marking programs, we will look for
In the content of the program, we will look for
For the moment (see later in this document) we also recommend
A slightly longer list of basic variable types in C++ is given below, together with their sizes in bytes on some implementations.
| type | PDP | 68000 | VAXVMS |
| char | 1 | 1 | 1 |
| int | 2 | 4 | 4 |
| long int | 4 | 8 | 4 |
| short int | 2 | 2 | 2 |
| float | 4 | 4 | 4 |
| double | 8 | 8 | 8 |
| unsigned int | 2 | ||
| unsigned long | 4 | ||
| unsigned short | 2 | ||
| unsigned char | 1 | ||
| (pointers | 2 | 4 | 4) |
The "unsigned" types are exactly what they say. They are used to store positive quantities, and can (in general) store a quantity twice a large as the corresponding signed type. You will be aware of the techniques used for the binary representations of integers. A 2-byte "int" variable would be able to store values ranging from
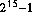
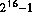
The compile-time operator "sizeof" gives the size of a supplied object in bytes, as in the example
main() {
int i;
cout << "Size is an int is "
<< sizeof i << "\n";
} // end main
By "compile-time" we mean that the calculated value is substituted into the program at the appropriate point by the compiler, not calculated at run-time.
Further, if in a program we had the expression
20 * sizeof i
(an operator with fixed values as its operands) we would expect the compiler to perform the multiplication once only at compile time; there would be no multiplications in the run-time of the program.
In C++ you may use a numeric value wherever a logical (Boolean) condition would be expected, because "zero" is always interpreted as FALSE, and "non-zero" as TRUE. If "n" is an "int", then the code
if ( n ) ... while ( ! n ) ...
is exactly equivalent to
if ( n != 0 ) ... while ( n == 0 ) ...
You will often see this terse version in C++ code. The two versions should be exactly equivalent when compiled.
The word "lazy" has a proper meaning in the compilation of programs. The "and" and "or" logical operators ("&&" and "||") are lazy, i.e. the operands are evaluated from left-to-right, and stop as soon as the result is determined.
i >= 0 && i < 10 && funct( i ) == 0 // evaluated left to right "lazy" // stop as soon as "false" is encountered
ok( "Overwrite file?" ) && ok( "Sure?" ) // Second prompt only if first ok
x < 0 || x >= 10 || ...
The "and" operator stops as soon as a false expression is encountered; the "or" stops as soon as a true expression is encountered.
This facility is just for the freaks, all normal mortals can ignore it. The following operators act upon a variable considered as a pattern of bits.
a << 2 // shifted left a >> 3 // shifted right a & 0177 // bit-by-bit AND a | 0100 // bit-by-bit OR a ^ 0100 // bit-by-bit excl OR ~ a // bit-by-bit negation
Such operations are normally performed on "unsigned" objects.
Declarations within a main program or function in C programs had to be placed at the start of the program/function, before any executable statements. That is the pattern I have followed in all my examples so far. This restriction has been relaxed in C++.
We refer to any section of the program or of a function from an opening curly bracket to the corresponding closing curly bracket as a "block".
C++ allows declarations to occur (almost) anywhere; each declaration is valid until the closing curly bracket matching the most recent previous opening one, i.e. to the end of the current block.
For example
main() {
// start outer block
int counter;
cin >> counter;
float recip = 1.0 / counter;
float total = 0.0;
while ( counter > 0 ) {
// start new block
float x = recip / counter;
total += x;
cout << counter << x << total << "\n";
counter--;
// x exists up to here
} // end while
cout << total;
// other variables exist up to here
} // end main
Each declaration is valid from the declaration until the closing curly bracket ending the block in which it was declared. By the word "valid" above we mean two things.
If an identifier is declared which is the same as an identifier in any outer enclosing block, the outer declaration becomes temporarily inaccessible until after the end of the inner block.
The declarations of "recip" and "x" above can be made "const" declarations, since the variable is not reassigned a different value. The declaration of "total" cannot be made constant, since its value is reassigned each time round the loop. If a value is not going to be reassigned, it is good practice for safety to use a "const" declaration to avoid it being accidentally overwritten. If you did this, you cannot accidentally write
if ( x = value )
since assignment to "x" would not be permitted.
You can also declare variables outside the main program and all of the functions. Such declarations are valid from the declaration right through to the end of the file. They can be referred to from anywhere in program or functions from the declaration to the end of the file. They will exists for the whole duration of the program.
If any identifier is re-declared in the program or a function (or in an inner block) the outer declaration again becomes inaccessible for that block.
Global variables are a convenient but dangerous way of communicating between functions, or between a function and the main program. For the moment, we recommend against their use. All information should be passed into and out of functions through their parameters.
This paragraph can be ignored by those who have not done programming before, and/or those who do not know what the word "GOTO" means (I certainly haven't mentioned it); you should skip to the following paragraph.
The preceding paragraph brings us to an interesting challenge. It has long been accepted that, generally speaking, a "goto" type of instruction is messy. I have not mentioned that C++ has a "goto" statement, and even if you realise that it has, you are not permitted to use it! There may however be a few occasions where it is helpful (it occurs several times in the huge amount of UNIX source code) but generally it encourages messy and tangled programming. The appearance of "goto"s generally indicates a poorly thought-out program. The use of "goto"s certainly makes the theoretical analysis of programs more difficult. For more discussion see Dijkstra's letter to the Editor of the Communications of the ACM, published March 1968, entitled "GO TO Statement Considered Harmful".
It spawned other articles such as "The Case Against the GOTO" by W A Wulf, (Proceedings of the 25th National ACM Conference, 1972, pp 791--), and "The Case for the GOTO" by M E Hopkins at the same conference. Most modern computer languages are designed to minimise the use of GOTO.
All readers start here! There are those in the real world who suggest that the use of assignment is equally harmful. You can perhaps appreciate that assignment makes proving things about programs more difficult, since the value of a given variable may change as we proceed.
The C++ feature that enables us to put declarations anywhere, and to use constant declarations, encourages a healthy train of thought to write complete programs using only constant declarations. The only other form of assignment permitted will be the use of "return" in a function, and, of course, the initialisation of constants is really a form of assignment.
The "Halberstam Function" of an integer value is defined as follows:
The Halberstam value of an integer value "n" is the number of times this operation needs to be repeated before the value 1 (one) is reached. It is guaranteed that you will eventually reach the value 1. If we start with the value 3, for example, the sequence goes 10, 5, 16, 8, 4, 2, 1; 7 steps. If we start with the value 7, the sequence goes 22, 11, 34, 17, 52, 26, 13, 40, 20, 10, 5, 16, 8, 4, 2, 1; 16 steps.
The old-fashioned solution declared as a function might typically be something like this:
int halberstam ( int n ) {
int value = n, count = 0;
while ( value != 1 ) {
if ( value % 2 == 0 ) { // Even
value = value / 2;
} else { // "value" is odd
value = 3 * value + 1;
}
// Count the times round the loop
count++;
} // while value not yet 1
return count;
} // end halberstam
This has two internal variables whose value is re-assigned each time round the loop.
A cleaner way might be on the following lines:
int halberstam( int n ) {
if ( n <= 1 ) {
return 0;
}
if ( n % 2 == 0 ) {
return 1 + halberstam( n / 2 );
}
return 1 + halberstam( 3 * n + 1 );
} // end halberstam
The above leads naturally to the concept of "recursion". "Recursion" occurs when you use a function within its own definition. Obviously you must be careful not to let the definition recurse indefinitely (infinitely), so a recursive definition will usually have an "escape clause" such as the "if ( n <= 1 ) ... " above. We may study the ideas of recursion in more detail later.
In ordinary UNIX commands, there are two distinct output streams for each command, the "standard output" and the "standard error" streams. When you divert output using redirection to a file or down a pipe, the error stream is not diverted; this ensures that error messages still come to the screen, to make sure the user is aware of the error.
In C++ programs, any output sent to "cout" is standard output, any sent to "cerr" is error output.
int total = 0, number;
while (
cin >> number,
number != 0
) {
if ( number < 0 ) {
cerr << "Invalid data "
<< number << "\n";
continue;
}
total += number;
} // end while number non zero
cout << "Total of valid data "
<< total << "\n";
Both of "cout" and "cerr" are declared in the standard "iostream.h" (or is it "stream.h"?) file.
Some later Ceilidh exercises may require that you print certain messages on the error stream, and other on the standard output. Don't forget to end "cerr" messages with a newline character. Output (on "cout" or "cerr") may not be printed if the terminating newline is missing.
Although we have not yet studied enough about arrays (collections of many objects of identical type, vectors) and pointers (addresses of objects) it will be useful to describe briefly how to use strings. When we study arrays later, all of this should make more sense.
The declaration
char name[] = "Eric Foxley";
gives an object called "name" initialised to the value given between quotes. You might print it using its identifier as in
cout << "My name is " << name << "\n";
If you declare an uninitialised string you must give it a size as in
char name[50];
which allows for a string of maximum length 49 characters; the fiftieth is used to contain a terminating null character. You can now read a string in using
cin >> name;
This will read characters from the input into the named string until white space (a space or tab or newline) is encountered. No checks are made to confirm that the length of the declared string is sufficient, so beware of chaos if the string read in is longer than the declared length.
There are library functions to do most of the things you might wish to do with strings. A few of the most useful are as follows.
int strlen( char [] ); char name[50]; cin >> name; cout << "length " << strlen(name) << "\n";
int strcmp( char[] , char[] );
char command[50];
while(
cout << "Type a command: ",
cin >> command,
1
) {
if (
strcmp( command, "edit" ) == 0
) {
... call editor ...
} else if (
strcmp( command, "print" ) == 0
) {
... call printer ...
} else if (
strcmp( command, "quit" ) == 0
) {
cout << "Bye!\n";
exit( 0 );
}
}
strncmp
to limit the number of characters which are compared as in the following example.
int strncmp( char[], char[], int );
if (
strncmp( command, "edit", 2 ) == 0
) {
... call editor ...
} else if (
strncmp( command, "quit", 1 ) == 0
) {
....;
}
The additional parameter limits the number of characters which will be compared. There is no need to put the full string into the program, but it helps readability.
char one[50], two[50]; cin >> one // copy string "one" into "two" strcpy( two, one );
It copies from the second parameter to the first.
For details of all such string functions, type
man string
at your terminal.
The compiler needs to know the declarations (as opposed to the definitions) of any string library functions which you use. Insteading of inserting these yourself, you should add the line
#include <string.h>
at the head of your program.
To pass strings to a function, the function declaration might be
void error( char[], int );
and the corresponding definition
void error( char message[], int number ) {
cerr << "Error " << message
<< " number " << number << "\n";
exit( 1 );
This function would be called as
error( "Negative number", 5 );
The parameter type given in the declaration is "char[]", and in the definition the parameter is specified as "char <name> []".
For keenies only, and please do not abuse it! You can use the system function in C++ to execute any UNIX command while your program is executing. If you write
system( "who" );
the program will execute the who command at this point just as if you had typed it from the keyboard.
The parameter can, of course, be the identifier of a string variable in which you have stored an appropriate command.
This is a feature which we will need on the near future.
The " #include " line which you already use is a general facility. The complete contents of the named file are substituted into your program instead of the "#include" line.
If the filename given is enclosed in "<" and ">" signs, the named file is searched for in a special system directory associated with the compiler and its function libraries. If the filename is enclosed in quote symbols, as in
#include "myheader.h"
then the named file is found in your directory and inserted in the text at this point in your program. The name can include a full path, as in
#include "/staff/eric/ceilidh.h"
To print your output more neatly, you may wish to use formatted output techniques. This corresponds to the use of "printf" in C. The function "form" takes as arguments a format string, and the values of expressions to be inserted in it. It is simplest to explain by example.
To print decimal values:
int i, j; cout << form( "%d times %d is %d\n", i, j, i*j );
The values following the format string are picked up and inserted for each "%" in order in the format. The rest of the format string is printed as it stands. The letter after the "%" specifies the type of format required.
To print floating values:
int i; float x; cout << form( "%d times %f is %f\n", i, x, i*x );
To print characters as such:
char ch; cout << form( "Char %c has ASCII code %d\n", ch, ch );
To print an integral value in octal:
int i; cout << form( "%d in octal is %o\n", i, i );
Possible other field definitions are
%3d // decimal, allow for 3 digits %03d // zero fill on left %-5d // allow 5 columns but left justify %10.3f // float, width 10, 3 DPs %s // string, see later %30s // string, 30 spaces, right justified %-30s // string, 30 spaces, left justified
Further examples:
cout << form(
"hours %d\nmins %d\nsecs %d\n",
h, m, s );
To print the time nicely:
cout << form( "time %2d:%02d:%02d",
h, m, s );
Copyright Eric Foxley Fri Dec 6 08:45:15 GMT 1996
Notes converted from troff to HTML by an Eric Foxley shell script, email errors to me!